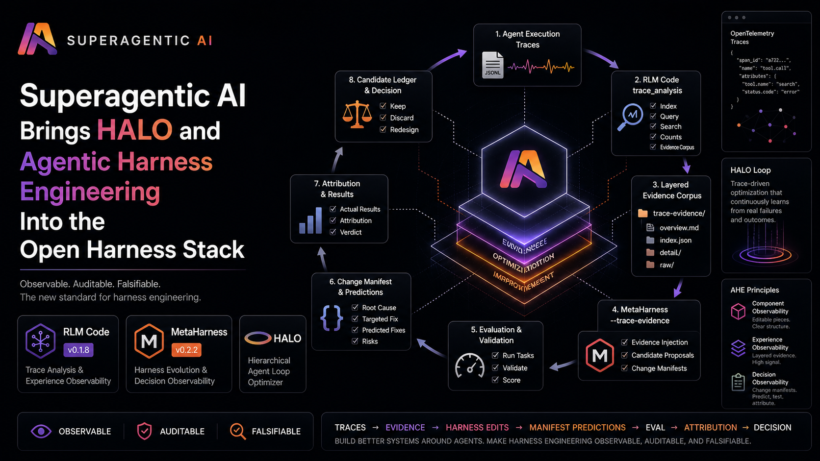
Harness engineering is moving from intuition to observability. Recent work around HALO and Agentic Harness Engineering (AHE) points to an important shift in agent development. The next frontier is not only building stronger coding agents. It is building better systems around those agents. The harness decides what the model can see, which tools it can use, how errors are surfaced, how traces are stored, and how improvements are evaluated. When the harness is weak, even strong models can fail in avoidable ways.
At Superagentic AI, we have now implemented the first practical version of these ideas across our open harness stack:
- RLM Code v0.1.8
- MetaHarness v0.2.2
This is not a clone of HALO or the AHE reference implementation. It is our own implementation of the core ideas inside our existing tools. HALO gives us the trace-analysis loop. AHE gives us the observability structure. RLM Code and MetaHarness now connect both into a working open-source harness optimization workflow.
The Problem: Harnesses Fail Quietly
Coding agents do not fail only because the model is weak. They often fail because the harness around the model is brittle.
Common harness-level failures include:
- Hallucinated tool calls
- Confusing or redundant tool arguments
- Missing feedback after failed commands
- Refusal loops
- Weak retry behavior
- Poor task decomposition
- Bad context compaction
- Unclear system prompts
- Middleware that hides useful state
- Evaluation signals that do not explain why a candidate improved or regressed
These are not only model-training problems. They are engineering problems. The challenge is that they are hard to debug manually. A serious benchmark run can produce thousands or millions of trace tokens. Reading raw logs by hand does not scale. Making random prompt edits is not enough either, because it does not reliably explain which change caused which outcome. This is where HALO and Agentic Harness Engineering become useful.
What HALO Showed
HALO, or Hierarchical Agent Loop Optimizer, showed that execution traces can be used as direct evidence for
harness improvement.
The basic loop is simple:
collect traces
-> analyze repeated failure modes
-> produce a report
-> feed that report to a coding agent
-> update the harness
-> evaluate again
The important part is that the optimizer is not guessing. It is grounded in what the agent actually did. If traces show hallucinated tool calls, the harness can add stricter tool-selection guidance. If traces show redundant tool arguments, the tool schema can be simplified. If traces show refusal loops, the system prompt or middleware can be changed. HALO made the trace-to-harness-improvement loop explicit.
What Agentic Harness Engineering Added
The Agentic Harness Engineering paper adds a stronger structure around the same idea. AHE frames harness optimization around three observability layers:
- Component observability: The harness should be decomposed into editable pieces such as prompts, tools,
tool descriptions, middleware, skills, memory, sub-agents, evaluators, and orchestration. - Experience observability: Raw traces should be distilled into layered evidence, including overview
reports, per-task or per-trace detail files, and raw traces for drill-down. - Decision observability: Every harness edit should come with a change manifest that explains what changed,
which evidence motivated it, what it is expected to fix, and what might regress.
This is the key shift. Prompt optimization says:
try a better prompt and see if the score improves
make an evidence-backed change
record the prediction
evaluate the result
attribute the outcome
keep, discard, or redesign based on evidence
That is a more serious engineering loop. It makes harness improvement observable, auditable, and falsifiable.
What Superagentic AI Built
Superagentic AI has implemented these concepts across two open-source repositories:
Together, they now support a practical workflow for trace-grounded, evidence-backed harness optimization.
RLM Code v0.1.8: Experience Observability
RLM Code now handles the trace-analysis side of the loop. We added a HALO and AHE-inspired trace_analysis environment that works over OpenTelemetry-shaped JSONL traces.
It supports:
- Sidecar trace indexing
- Dataset overview
- Trace querying
- Trace counting
- Trace search
- Full trace viewing for small traces
- Selected span viewing for large traces
- Bounded payload handling
- Layered evidence corpus export
The new core action is:
export_evidence_corpus
This writes a structured evidence bundle:
trace-evidence/
overview.md
index.json
detail/
trace-error-1.md
trace-error-2.md
raw/
trace-error-1.jsonl
trace-error-2.jsonl
The output is designed for another coding agent or MetaHarness to consume.
overview.md gives the high-level diagnosis. detail/*.md gives per-trace evidence. raw/ keeps processed span data available for drill-down.
*.jsonlindex.json makes the corpus machine-readable. This implements the AHE idea of experience observability. Traces are not dumped into a prompt blindly. They become a layered evidence corpus.
Example workflow:
/rlm run "Find systemic harness failures trace=./traces.jsonl" env=trace_analysis steps=6
Then export the evidence corpus:
{
"action": "export_evidence_corpus",
"output_dir": "./trace-evidence",
"filters": {"has_errors": true},
"limit": 100,
"include_raw": true
}
The resulting trace-evidence/overview.md can then be passed into MetaHarness.
MetaHarness v0.2.2: Decision Observability
MetaHarness now handles the harness evolution side. We added support for trace-grounded candidate generation and AHE-style change manifests. MetaHarness already creates candidate workspaces, runs proposal backends such as Codex or Gemini, validates changes,
evaluates candidates, and stores run artifacts.
Now it also supports:
--trace-evidence- Candidate evidence injection
.metaharness/evidence/trace_evidence.md.metaharness/change_manifest.json- Archived proposal manifests
- Optional task-level change attribution
- Ledger fields for changed components and verdicts
A MetaHarness run can now receive trace evidence like this:
uv run metaharness run ./my-harness \
--backend codex \
--hosted \
--trace-evidence ./trace-evidence/overview.md \
--budget 1
Each candidate workspace receives:.metaharness/evidence/trace_evidence.md The proposer prompt explicitly tells the coding agent to use that evidence when making harness changes. Before finishing, the proposer is now instructed to write:
.metaharness/change_manifest.json
A manifest looks like this:
{
"schema_version": "metaharness.change_manifest.v1",
"candidate_id": "c0001",
"parent_candidate_ids": ["c0000"],
"changes": [
{
"id": "change-1",
"component": "tool_description",
"description": "Clarified the tool argument contract.",
"files": ["tools/search.py"],
"failure_pattern": "The agent repeatedly passed redundant arguments.",
"evidence_refs": ["trace_evidence.md#trace-error-1"],
"root_cause": "The tool schema allowed ambiguous argument combinations.",
"targeted_fix": "Make the required argument explicit and remove redundant alternatives.",
"predicted_fixes": ["task-search-001"],
"risk_tasks": ["task-search-legacy"],
"notes": "Should reduce malformed tool calls."
}
]
}
MetaHarness archives this under:candidates/<id>/proposal/change_manifest.jsonIf the evaluator returns task-level results, MetaHarness can also generate:
candidates/<id>/proposal/change_attribution.json
That attribution report compares predicted fixes, risk tasks, actual improvements, and regressions. Verdicts include:
EFFECTIVEPARTIALLY_EFFECTIVEMIXEDINEFFECTIVEHARMFUL
This gives MetaHarness a real decision ledger. The point is not just to find the winning candidate. The point is to
understand why a change worked or failed.
The New Superagentic Harness Loop
Together, RLM Code and MetaHarness now support this loop:
agent execution traces
-> RLM Code trace_analysis
-> layered evidence corpus
-> MetaHarness --trace-evidence
-> candidate harness edits
-> change_manifest.json
-> validation and evaluation
-> change_attribution.json
-> candidate ledger
-> keep, discard, or redesign
This is the practical implementation of HALO and AHE concepts in the Superagentic AI stack.HALO-style trace analysis gives us the evidence. AHE-style manifests make the decisions auditable. MetaHarness turns that into an optimization workflow.
Why?
This moves harness optimization away from guesswork. Instead of saying:
The new prompt seems better.We can say:
This candidate changed the tool description because traces showed malformed tool calls.
It predicted task A would improve and task B might regress.
After evaluation, task A improved and task B stayed stable.
The change is EFFECTIVE.That is a stronger engineering primitive. It makes harness improvement:
- Observable
- Reproducible
- Auditable
- Benchmarkable
- Falsifiable
This is especially important for coding agents because the harness is now a large part of the product.
The model is only one part of the system. The real agent experience comes from the model plus tools, memory, middleware,
prompts, execution environment, tracing, evaluation, and rollback behavior.
What We Did Not Do
We did not copy the HALO repository. We did not copy the AHE reference implementation. We did not tie our stack to NexAU,
Harbor, E2B, or any one benchmark runtime.
Instead, we implemented the transferable ideas:
- Trace analysis
- Layered evidence
- Evidence injection
- Change manifests
- Task-level attribution
- Candidate ledgers
This keeps the Superagentic AI stack modular.
RLM Code remains the recursive trace-analysis and experimentation layer. MetaHarness remains the optimization and candidate-
evaluation layer. The two now work together.
What Comes Next
This is the first practical version of the loop.
Next, we plan to improve the system in several directions:
- Richer task-level grouping in RLM Code
- Automatic MetaHarness ingestion of the full evidence corpus, not only
overview.md - Better component-level rollback suggestions
- Stronger OpenTelemetry compatibility
- Multi-run attribution across candidates
- Benchmark reports showing before and after gains
- Tighter integration between trace spans and candidate manifests
The long-term direction is clear:
self-improving harnesses need observability firstBefore an agent can improve its own harness, it needs to see what happened, understand what changed, and verify whether the
change worked. That is what we have started building.
Summary
Superagentic AI has now implemented HALO- and AHE-inspired observability loops across its open harness stack. In RLM Code v0.1.8, we added layered trace evidence export. In MetaHarness v0.2.2, we added trace-grounded candidate proposals, change manifests, task-level attribution, and candidate ledger support.
Together, they create a practical open-source workflow for observable harness optimization:
traces -> evidence -> harness edits -> manifest predictions -> eval -> attributionThis is the beginning of falsifiable harness engineering.